
ADVERTISEMENT
2022年,生成模型(Generative models)取得了巨大的進展。不僅可以從自然語言提示中生成逼真的 2D 圖像,也在合成影片和 3D 形狀生成方面有著不俗的表現。
雖然目前的生成模型可以生成靜態的 3D 物件,但合成動態場景更加複雜。而且,由於目前缺少現成的 4D 模型集合(無論是有或沒有文字注釋),相比於 2D 圖像和產生影片,由文字到 4D 的生成更加困難。
那麼,如何基於簡單的文字直接產生複雜的 3D 動態場景呢?
一種可能的方法是,從預先訓練好的 2D 影片產生器開始,從產生的影片中提取 4D 重建。然而,從影片中重建可變形物體的形狀是一項非常具有挑戰性的工作。
近日,來自 Meta 的研究團隊結合影片和 3D 生成模型的優點,提出了一個新的文字到 4D(3D+時間)生成系統——MAV3D(Make-A-Video3D)。
據介紹,該方法使用 4D 動態神經輻射場(NeRF),透過查詢基於文字到影片(T2V)的擴散模型,對場景外觀、密度和運動一致性進行了最佳化。
同時,由特定文字生成的動態影片可以從任何攝影機位置和角度觀看,並且可以合成到任何 3D 環境中。

研究團隊表示,MAV3D 是第一個基於文字描述產生 3D 動態場景的方法,可以為電玩遊戲、視覺效果或 AR/VR 產生動畫 3D 資產。相關研究論文以「Text-To-4D Dynamic Scene Generation」為題,已發表在預印本網站 arXiv 上。
據論文描述,MAV3D 的實現不需要任何 3D 或 4D 資料,而且 T2V 模型也只是在文字-圖像對和未標記的影片資料上訓練的。
以往研究證明,僅僅使用影片生成器最佳化動態 NeRF 不會產生令人滿意的結果。為了實現由文字到 4D 的目標,必須克服以下 3 個挑戰:
- 找到一個端到端、高效且可學習的動態 3D 場景的有效表示;
- 有一個監督來源,因為沒有可供學習的大規模(文字,4D)資料集。
- 需要在空間和時間上縮放輸出的解析度,因為 4D 輸出域是記憶體密集型的和運算密集型的。
那麼,由簡單的文字描述到複雜的 3D 動態場景生成,具體是如何實現的呢?
首先,研究團隊僅充分利用了三個純空間平面(綠色),算繪單個圖像,並使用 T2I 模型運算 SDS 損失。
然後,他們添加了額外的三個平面(橙色,初始化為零以實現平滑過渡),算繪完整的影片,並使用 T2V 模型運算 SDS-T 損失。
最後,即超解析度微調(SRFT)階段,他們額外算繪了高解析度影片,並將其作為輸入傳遞給超解析度元件。
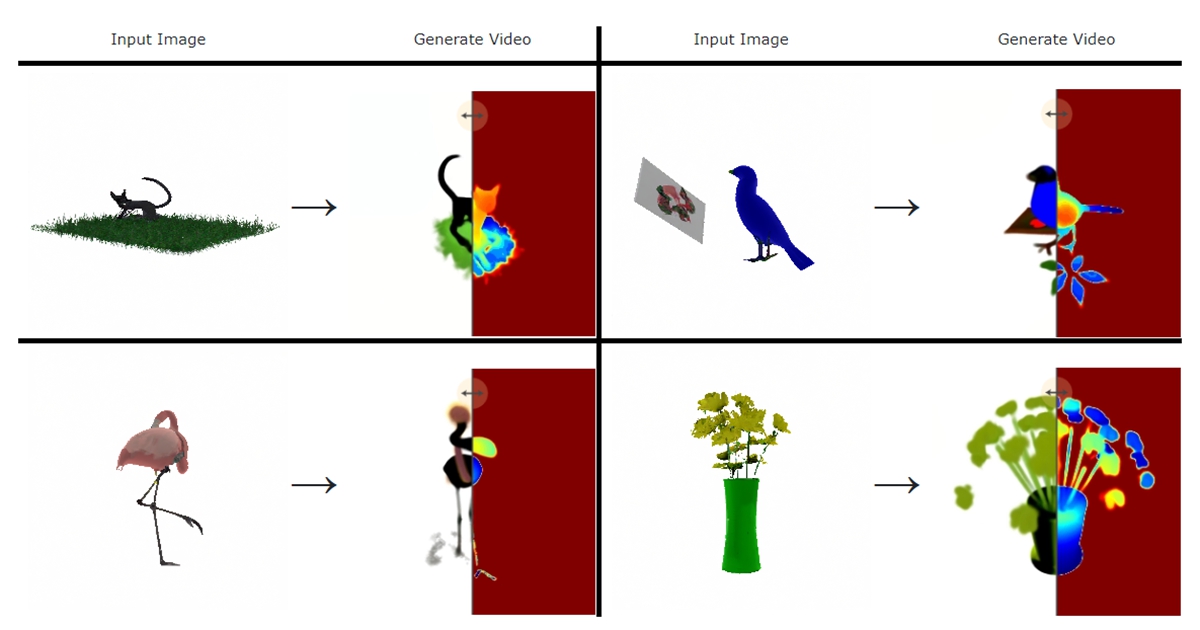
另外,MAV3D 也可以完成由圖像到 4D 應用的轉換。給定一個輸入圖像,透過提取它的 CLIP embedding,並以此來約束(condition)MAV3D。
然而,這一方法也存在一定的局限性。例如,在即時應用中,將動態 NeRF 轉換為不相交網格序列的效率很低。研究團隊認為,如果直接預測頂點的軌跡,或許可以改進。
此外,利用超解析度資訊已經提高了展示的品質,但對於更高細節的紋理還需要進一步改進。
最後,表示的品質取決於 T2V 模型從各種視圖生成影片的能力。雖然使用依賴於視圖的提示有助於緩解多面問題,但進一步控制影片產生器將是有幫助的。
資料來源:

請注意!留言要自負法律責任,相關案例層出不窮,請慎重發文!