
ADVERTISEMENT
Intel執行長Pat Gelsinger在Vision 24大會宣佈與合作夥伴共建AI開放平台,並展示RAG技術,讓現有大型語言模型能夠搭配具有新資訊的資料庫,快速更新AI的「認知」。
快速部署私有LLM
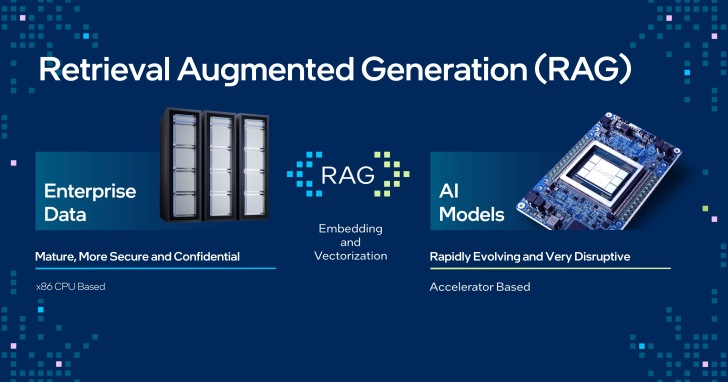
目前使用大型語言模型(Large Language Model,以下簡稱LLM)的一大問題,就是LLM僅擁有的訊練當下所輸入的資訊,而對於訓練之後所發生的事件一無所知。舉例來說,使用截至2023年的資料所訓練的LLM,可能很擅長回答2022年的資訊,但若詢問2024年的資訊,可能就會出現錯誤甚至得到「無法回答」的結果。
然而加入新資料並重新訓練LLM並不是件簡單的事,過程需要花費許多時間與電力(意味著高額電費或是伺服器租賃費用),若以每月或是每週的頻率重新訓練,將衍生沉重的成本負擔。
而檢索增強生成(Retrieval Augmented Generation,以下簡稱RAG)則是能在現有LLM之上「外掛」包含有新資料、文件、檔案的資料庫,讓LLM能夠自動從資料庫尋找資訊,簡化加入新資料的工作流程。
另一方面Intel也攜手Anyscale、DataStax、Domino、Hugging Face、KX Systems、MariaDB、MinIO、Qdrant、RedHat、Redis、SAP、SAS、VMware、Yellowbrick和Zilliz等合作夥伴,宣布建立適合企業AI的開放平台,協助企業快速導入LLM與各種AI解決方案。
企業AI開放平台也能與RAG相輔相成,企業能夠下載開放的LLM搭配私有資料庫,並整合為能夠回答包含私有資訊的聊天機器人,實現效益更高的部署便利性、最佳效能和價值,並且落實在本地端進行AI推論以降低資安風險,強化企業的生成式AI應用。

RAG協助回答即時資訊
Pat Gelsinger也在Vision 24大會演說上進行RAG的實際展示,展現RAG能夠協助使用者爬梳資訊,由資料庫中的文件檔案找出具有參考價值的回答。
有興趣瞭解更多資訊的讀者,可以到Intel官方網站觀看Vision 24大會演說的精華片段,以及更多技術展示。

請注意!留言要自負法律責任,相關案例層出不窮,請慎重發文!