
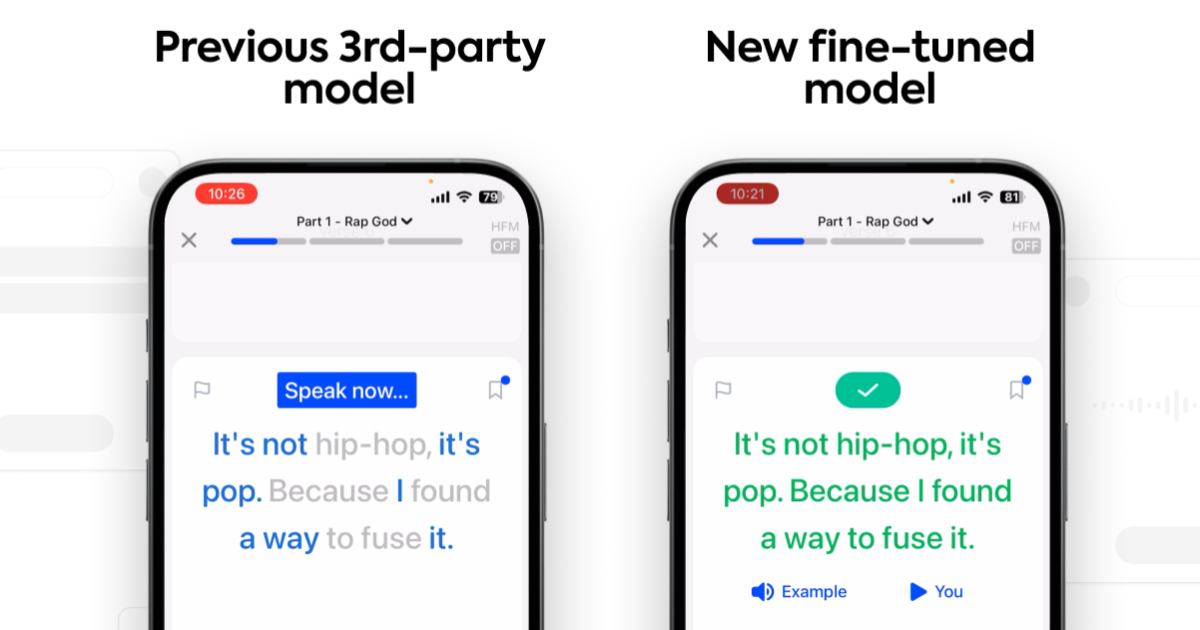
人工智慧語言學習平台 Speak 為打造低延遲、高辨識度的英語口說識別服務,近日宣布整合分散各平台基礎架構上的訓練數據,全面升級核心語音辨識系統。此升級使 Speak 更能貼近實際使用場景,能有效辨識各種帶有口音的英語。與之前的模型相比,新模型將字詞錯誤率降低了 45%,整體字詞錯誤率更是減少超過 60%,大幅提升 Speak 服務中口語回饋的準確性與可靠性。
解決數據來源分散問題,Speak 運用 NVIDIA NeMo 加速模型訓練
為有效在單一後端系統上整合來自各個平台來源的數據進行模型訓練,Speak 選擇使用 NVIDIA 為研究和開發語音和大語言模型所開發的端對端雲原生開源框架- NVIDIA NeMo ,以加速分散式訓練和模型的開發維運。整合自動語音辨識模型推理及後處理邏輯,Speak 將核心語音基礎架構重新打造為單一且更大型的後端系統,導入來自全球 Speak App 中的學習者數千小時、帶有各地濃厚口音的英語語音作為訓練數據集,將 Speak 所有數據集整合,簡化維運並確保所有用戶和裝置都能獲得即時且高效的服務回饋。
根據 Speak 以字詞錯誤率為指標針對其新模型效能進行的評估,整體字詞錯誤率減少超過 60%,相較於預訓練模型有了顯著的進步,大大增強了 Speak 核心口語回饋循環的可靠性和可信度,主因來自於其導入訓練的數據集完全在特定領域內,並且涵蓋了多種強烈口音,而這些口音是現成的模型仍然難以處理的。

訓練全球 Speak App 中的南腔北調,全面提升用戶即時互動的體驗
為了讓新模型可以更精確的識別用戶的英語口語,Speak 使用了 Conformer 語音辨識模組(一種用於音頻和語音處理的深度學習模型結構,用於語音識別和自然語言處理任務),並以微調後的 Conformer-CTC 架構訓練全球 Speak 帶有濃厚口音的英語語音數據集,以快速辨識長串語句的關聯字詞,並根據上下文語意特徵,快速給予反饋。
除了升級訓練模組加速自動語音辨識系統,為了提升用戶即時互動的體驗,Speak 將微調後的Conformer-CTC 架構,部署並運行在 NVIDIA Riva 上(NVIDIA Riva 是一組GPU 加速的多語言語音和翻譯微服務),讓音頻數據在系統和用戶端之間的傳遞更加高效,加速實時的雙向互動。
Speak 表示,過去從提示用戶開始說話並錄音的那一刻起,用戶平均需要大約 1.6 秒才能收到第一個口語的回饋,「但使用升級的系統架構之後,相較於以前使用協力廠商的語音辨識服務,平均速度提高了 20%。」Speak 還會根據每日流量在不同時間的高低不同來擴展 Riva 節點,並確保至少每 260 毫秒提供一次回饋,能夠達到與日常對話中人類的平均反應時間接近。
Speak 新一代的核心語音辨識系統為用戶提升了口語回饋速度和準確度,透過新的模型訓練和部署基礎架構,Speak 將能夠快速反覆運算更現代的模型架構,持續擴展的語音數據集,未來還能以此基礎架構來服務定制的大型語言模型(LLM)和多模態/語音到語音模型。目前,Speak自行調整的 Conformer-CTC 模型僅用於英語語音辨識,但 Speak 未來計畫將其擴展到西班牙語及更多其他語言,讓用戶透過 Speak 享受即時互動的語言學習體驗。

請注意!留言要自負法律責任,相關案例層出不窮,請慎重發文!