
ADVERTISEMENT
NVIDIA首次提交由專為AI推論運算設計的GB200 NVL72機架規模解決方案之測試成績,較H200 NVL8結果高出30倍。
同時Scale Up與Out
最新MLPerf 5.0推論測試加入參數數量超大的Llama 3.1 405B、更嚴格要求延遲的Llama 2 70B Interactive等大型語言模型(Large Language Model,LLM),以及R-GAT圖像注意力網路等項目。
延伸閱讀:NVIDIA公布MLPerf Training 4.1測試成績,DGX B200系統GPU效能提升最高達2.2倍
NVIDIA表示,在近1年的時間之內,H100 NVL8透過軟體最佳化的方式,在Llama 2 70B項目達到1.5倍成績,若以強化記憶體頻寬的H200 NVL8進行測試成績則可達到原來的1.6倍。
至於Blackwell世代部分,B200 NVL8的表現可達H200 NVL8的3倍,至於規模更大的GB200 NVL72在將成績表準化為8個GPU時,表現也能達到H200 NVL8的2.8~3.4倍,而原始效能則可達H200 NVL8的25~30倍。
從前後世代對照可以看出,Blackwell世代的效能較前代Hooper提高約3倍,達到Scale Up的效能提升效果,而GB200 NVL72最多可在單一叢集中串連72組GPU,高於H200 NVL8的8組,則為Scale Out的向外拓展效果。

更強的硬體滿足更大的需求
NVIDIA也表示,隨著AI運算的模型參數量越來越大,以及執行長黃仁勳於GTC 2025春季場開幕演說提到推理式AI採用的測試時訓練、延長思考時間(思考過程需花費更多字詞),且使用者輸入的文本也越來越長,都會堆高AI運算的需求。
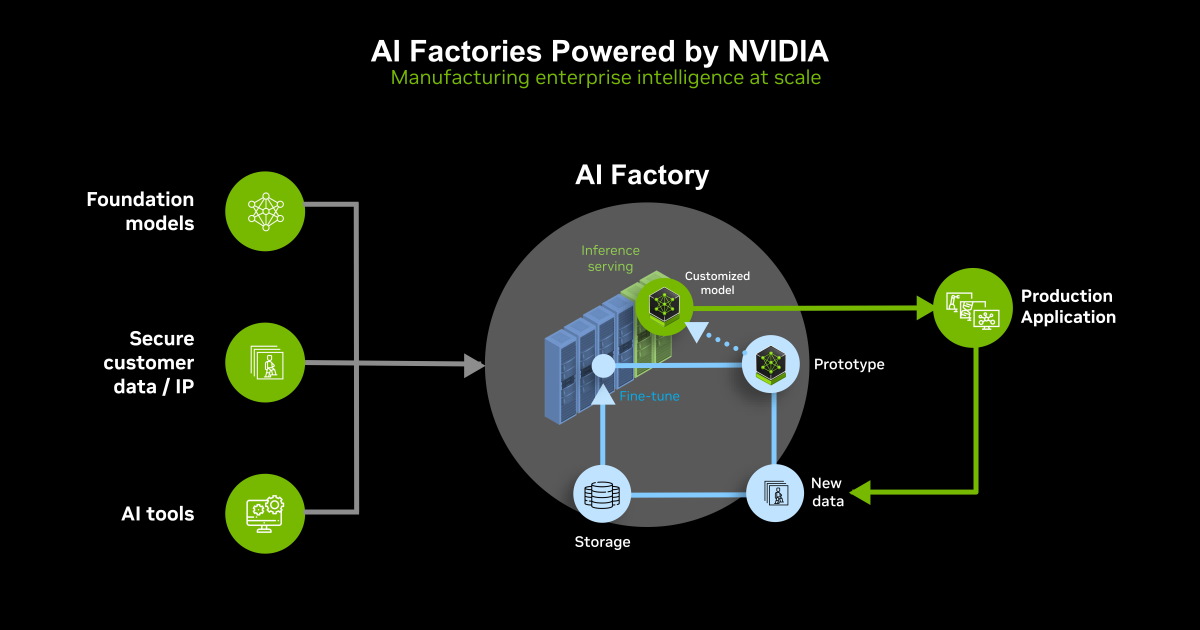
另一方面,AI工廠的商業模式也越加成型,客戶輸入基礎模型搭配私有資料與AI工具,在資料中心的伺服器運算後產出客製化模型與應用程式,也提升運算能力的整體需求。
NVIDIA強調能為AI工廠提供完整的軟、硬體堆疊,上從各種AI藍圖(Blueprints)、企業管理工具、AI推論軟體,到運算單元與網通單元等硬體裝置,並提供NVIDIA認證系統,搭配儲存裝置與資料中心的基礎設施,就能建構完整AI工廠。
更多關於NVIDIA對AI發展趨勢的分析,可參考先前《【GTC 2025】黃仁勳演說深入分析:提出「終極摩爾定律」,追求相同耗電更高效能》一文。

請注意!留言要自負法律責任,相關案例層出不窮,請慎重發文!