

ADVERTISEMENT
Intel 終於在屆滿三週年的此時,推出了新一代家用旗艦平台:Haswell-E,架構全面革新,首次搭載 DDR4 記憶體。搭配的晶片組也一併更新為 X99,Haswell-E 擁有前朝 Ivy Bridge-E 的光環,是否能再稱霸下個 3 年?
處理器概念篇
在解禁前,大部分使用者對於 Haswell-E 的認識,大多僅留存在家用平台首個 8 核心處理器、第 1 款採用 DDR4 記憶體的處理器。本篇將會著重設計層面的解析,對本次改進了什麼、沿用了什麼,以及新功能導入一一進行介紹。

▲最初曝光的文件中,指名會支援 8 核心、DDR4 記憶體。
核心全面 6 核心起跳
Ivy Bridge-E 最令人詬病的原因之一在於核心數量,雖然已經達到 6 核心 12 執行緒,不過在玩家眼中,Core i 家族中始終缺少了更多核心數量的產品,連對手 AMD 都已經推出 8 核心平台,反觀 Intel 仍然還停留在 6 核心產品上。而這次 Haswell-E 終於將核心數量提升為 8 核心,同時最低階型號也一併更新為 6 核心,加大與家用主流效能平台之間的差別。
導入 DDR4 記憶體支援
Haswell-E 也是首個支援 DDR4 記憶體的處理器,雖然與 Haswell Refresh 系列屬於同個架構產物,不過 Intel 在更早的前幾代產品中,就已經導入模組化概念。透過模組概念,針對不同區間的產品進行修改,或者加入新模組設計,簡化整體核心開發時程。但這次不同之處在於並不向下支援 DDR3,而是直接捨棄,不會有當初 DDR2、DDR3 造成混亂的局面。
插槽腳位改變
雖然腳位數量仍然為 2011 個,不過眼尖的讀者可能早已發現,兩者在數量上並不一樣。前代產品金屬點為 2011 個,不過 Haswell-E 是超過 2011 個,多出來的腳位分別位於處理器外圍 6 處。當然這些多出來的金屬點並非裝飾用途,而是具備一些隱藏功能,如電壓偵測、加壓等。不過主機板上的插槽分為 2 種版本,其一為針腳數量 2011 個的正常版,其二則是特製品,提供全數針腳具有其他作用。

▲左邊為 LGA 2011,右邊為 LGA 2011-3。

▲正常版的 Socket 周圍 6 角都是無接點設計。

▲特殊版的 Socket 則是金屬點全滿。
新舊兩代改了什麼、沿用什麼?
新舊兩代的差異其實非常明顯的只有 2 個重點:DDR4 與 FIVR 導入,前面為新的記憶體支援,後者為 Haswell 世代處理器所內建調壓模組。那沿用了什麼?3D Tri-Gate Transistor、導熱介質,還有 LLC,處理器組成大架構,這些都是沿用前代產品的設計。
DDR4 導入,全新記憶體架構
DDR4 與 DDR3 之間的不同之處在於加入 Bank Group 架構,點對點傳輸、3DS、TSV 加持。相比 DDR3 的單 Bank 設計,DDR4 導入 Group 概念,因此不需要再提昇顆粒時脈,即可得到更大的頻寬。
另外在 Prefetch 上,也不需要從 8N 增加至 16N,這對線路設計還有複雜度都可大幅簡化。Bank Group 能讓資料傳輸更有效率,主因在於運作情形的改變,以往 DDR3 單 Bank 架構下,資料會對同個 Bank 進行存取,相對會增加延遲。
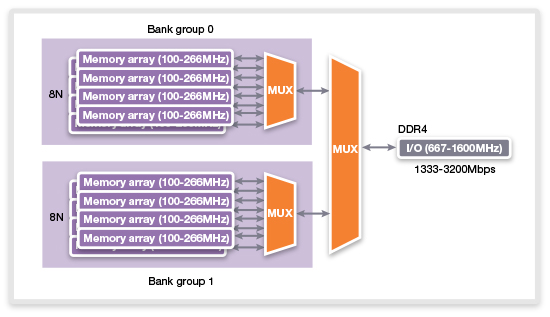
▲ DDR4 導入 Bank Group 概念,不用提昇 Prefetch 即擁有同等效果。
DDR4 導入 Bank Group,可分為 2 種存取情境,分別在不同 Bank Group 間存取,或者是在同個 Bank Group 底下進行不同 Bank 存取。兩者之間將會有著延遲差異,前者相對較佳(tCCD_S),後者則是造成大量延遲的主因(tCCD_L)。
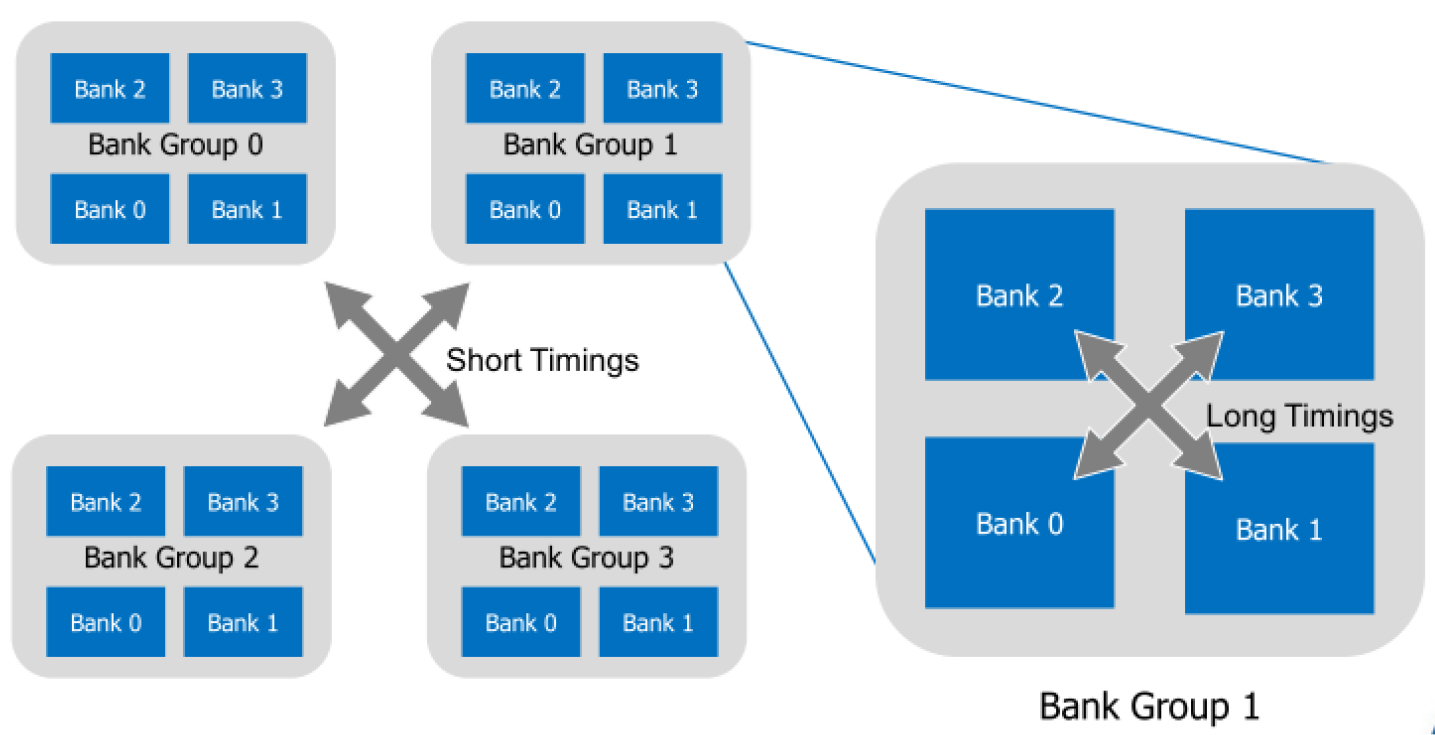
▲左邊為 tCCD_S、右邊為 tCCD_L,兩者的延遲為右大於左。
點對點傳輸則是大幅改進同個匯流排底下的記憶體搶頻寬問題,在以往的 DDR 架構下,採用共用匯流排設計,也就是說廠商可以針對需求進行數量增加或減少,並不局限於記憶體控制器,唯一受限制的為 Rank 數。
而在 DDR4 則是 1 個記憶體控制器通道對應 1 個插槽,兩者間為點對點傳輸,並不會受其他記憶體影響,也就沒有搶頻寬問題。但此舉也相對增加容量擴充上的限制,因採用單一結構導致記憶體容量因此受到單條記憶體限制,較以前依照插槽數量提昇容量的狀況複雜,但也催生了 3DS、TSV 等解決方案。
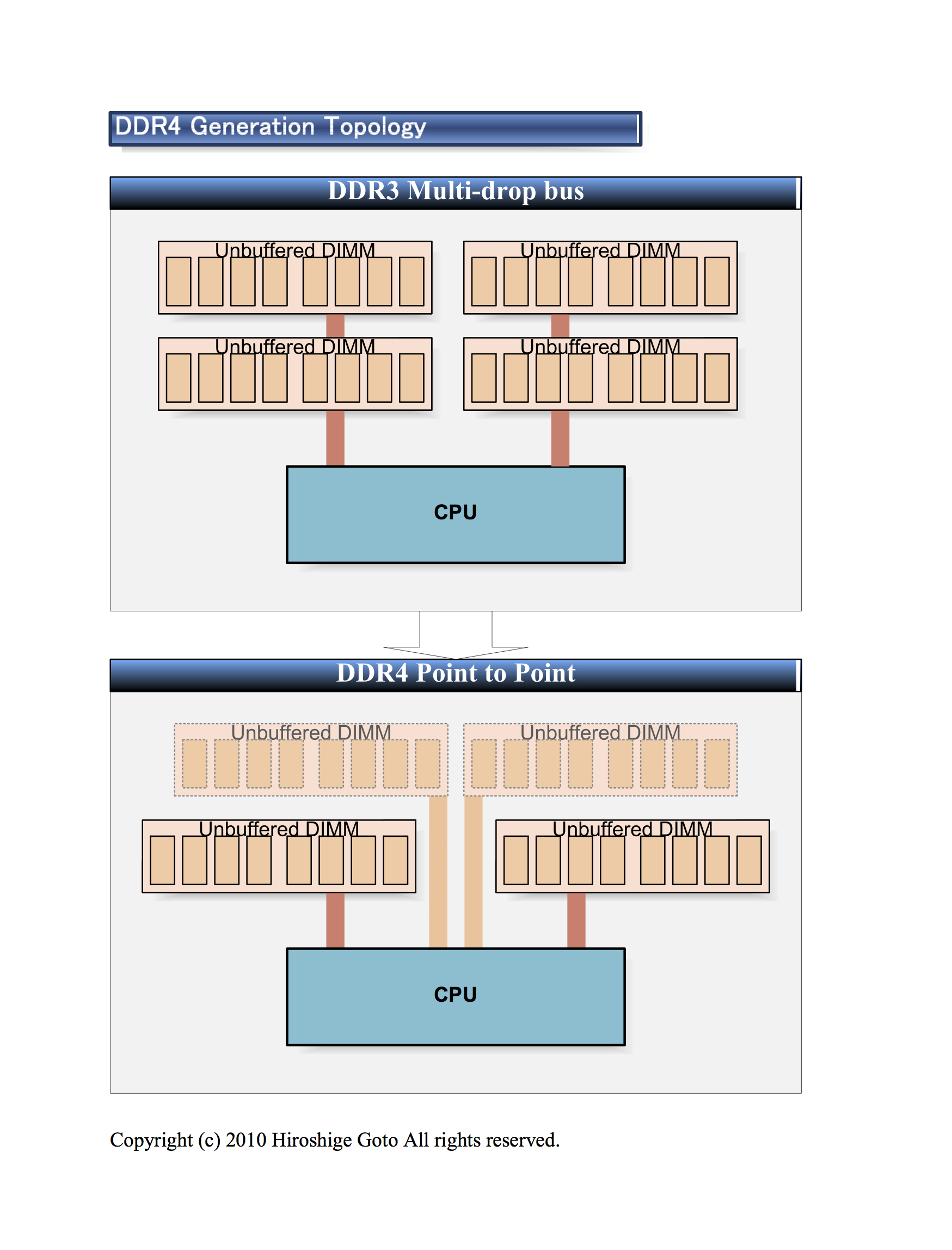
▲DDR4 將會改用點對點架構,單一記憶體使用獨立通道。(圖片取自:pc.watch)
3DS、TSV 分別代表 3D-Stack(3D 堆疊)、Through Silicon Via(矽穿孔)前者為顆粒堆疊方式,將原先的單晶圓封裝,藉由堆疊的方式增加單一面積下多晶圓堆疊數量。不過這也衍生另一問題,堆疊後的管線需從何生,TSV 便是這個問題的解決方案。藉由矽穿孔的方式,讓管線穿透晶圓與之上的晶圓做連結,解決晶圓與 PCB 間的管線連接問題,此舉也就解決容量不易增加的困擾。
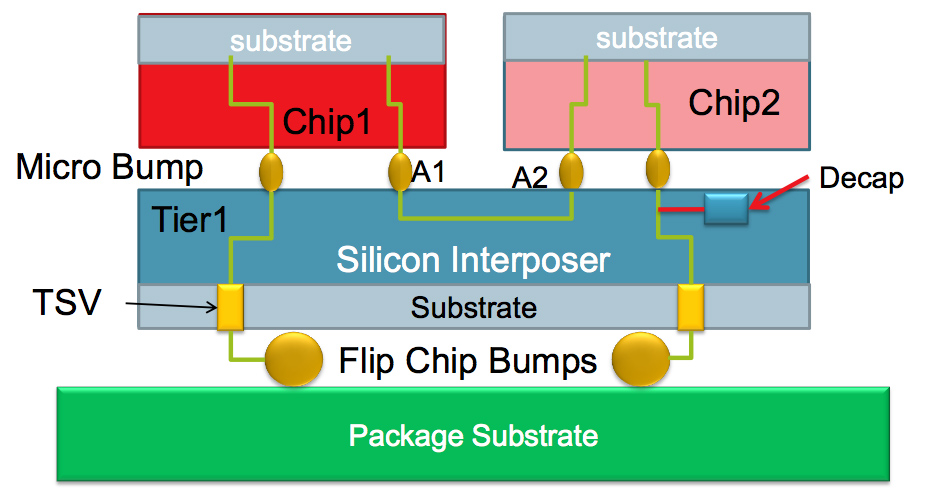
▲初期的 TSV 採用在 Silicon Interposer 內達成晶片間溝通。

▲新的 TSV 則是將會直接將矽晶圓連接。
導入 FIVR,廠商簡化設計
在 FIVR 之前,處理器的電壓都是透過外部 VRM 提供,VRM 之外還需要 PWM 控制,同時電流限制也因部分元件而受限制,FIVR 模組即是這個解決方案的終極版。
晶圓內建整套的電壓調整模組,廠商將可以大幅減少外部迴路設計,將原先的複雜線路簡化為單一供電。以往我們的處理器對於電壓需求大多分為 Core、Uncore 兩個部分,Core 即是 Core VR,而 Uncore 則是包括 Graphic、PLL、System Agent、I/O 等電壓。
FIVR 則是將這些電壓全數整合為 Input VR,也就是說以往各部分開的不同電壓調節,需針對各電壓進行設計迴路,現在只需要單一迴路即可。這可以簡化廠商設計,目前只需要 2 個迴路,分別為 Input VR 對處理器供電、另一個為 Mem VR 對記憶體供電。
設計上也變更為以電流上限為主,FIVR 因在內部能夠達到 140MHz 高速的開關頻率,相對外部迴路僅有 1MHz 的頻率,效率強化數倍也減低整體 Rds(on)。Intel 的 FIVR 內部模組最高為 20 個 Power Cell,單 1 個為 16 相設計,每 1 個上限是 25A,共計 320 相、500A 的跨時代設計,這一點為目前外部迴路所不可能達到的目標。
也因此廠商設計時,只需要針對 500A 這個規格進行設計即可,並不需要強求電壓的調整能力。以華碩的通用設計來看,8 相迴路單相負載為 40~60A,這樣組成 320A~480A 即可滿足 FIVR 的運作要求。外部迴路追求多相數或更高檔的用料兩者之間,前者意義並不大,後者則是降低外部迴路12V 電壓降壓輸入 FIVR,所產生廢熱較少的主因。

▲Intel FIVR 架構,能夠簡化外部迴路設計。(點圖可放大)
沿用前幾代設計
3D Tri-Gate Transistor、導熱介質,還有 LLC 這些都是沿用上代旗艦設計,其中 3D Tri-Gate Transistor 中文為 3D 三柵極電晶體,改進 2D 結構在 30nm 後的漏電流問題。為了在 22nm 下讓電晶體穩定運作,必須對柵極加入更大電流才得以穩定,此舉將會增加廢熱問題。
而 3D Tri-Gate Transistor 則是將原先的一維結構改為三維立體,能夠帶來更高的效率與降低功耗,比起傳統電晶體結構都有大幅度的提升,與 3D Tri-Gate Transistor 齊名的則是還有 FinFET(鰭式場效電晶體),柵極類似魚叉狀,採用多 1 個柵極解決漏電流問題。
不過改為三維立體結構後,改善發熱問題,但也帶來硬體上的限制。由於是三維立體堆疊的方式,將會比原先的一維更難解熱,熱量將會堆積在內部而不容易發散,這也是目前面臨到的最大問題。
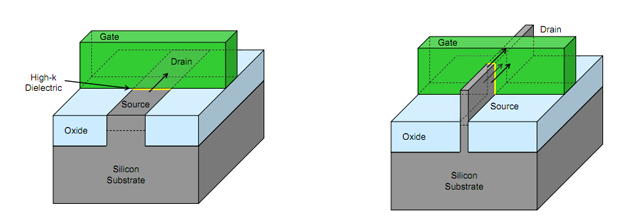
▲3D Tri-Gate Transistor 架構,將原先一維平面改為三維立體。
另外在處理器所使用的 TIM(Thermal Interface Material:內部散熱介質)將會採用 Ivy Bridge-E 上所使用的釺焊,將會減低 Haswell Refresh 因採用散熱膏,而產生的異質熱阻問題。在熱的傳導上,會隨著材質而有著不同的熱阻,散熱膏即使具備出色導熱係數,仍然比使用釺焊技術將 2 異質金屬融合,所產生的熱阻要來的高上數倍。
尤以 3D Tri-Gate Transistor 以降,發熱量更高,需要高效率的熱傳導,採用散熱膏填補矽晶圓與鐵蓋之間的間隙,顯然在高熱量的 Haswell-E 上不適用,而釺焊技術則是目前的首選,也是 Intel 在高階處理器上所使用的填充物。
LLC(Last Level Cache)則是目前 Intel 在 Cache 上對於所有處理器所做的設計,LLC 通俗一點的講法為 L3 快取,不同於 L1、L2 各核心專屬且不共用的設計,LLC 採用全核心共享,可加速各核心之間的溝通,同時因為是全面共享的結構,各部份可單獨存取,也可以不同核心存取同一份資料,大幅減低延遲問題。
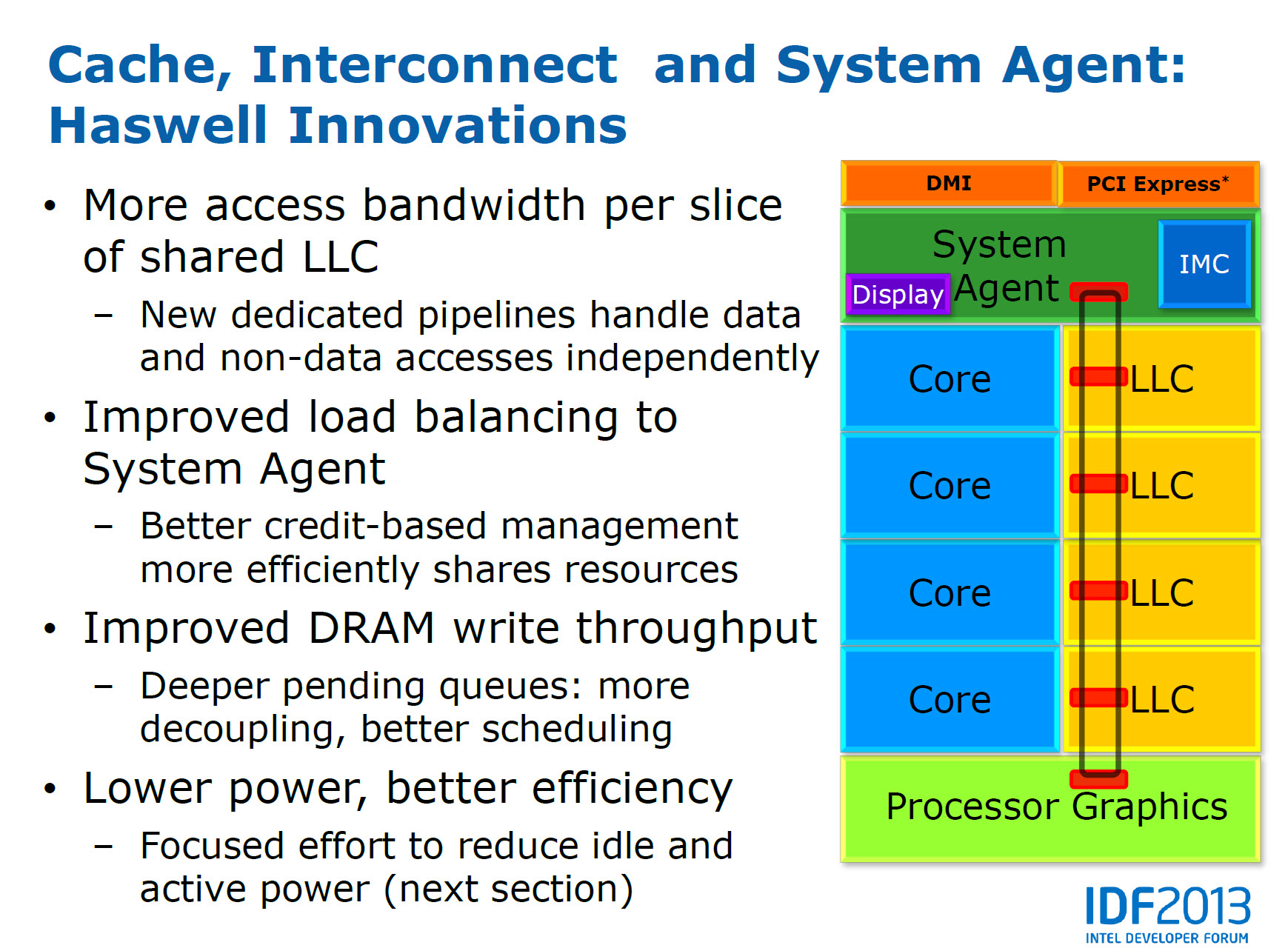
▲LLC 架構用意在於縮短快取之間的溝通延遲。
下個三年旗艦?
看完基本的 Haswell-E 改進、沿用的架構後,可以發現進步幅度雖不小,但仍然有些遺珠。如與 X99 晶片溝通的橋樑仍然為 DMI 架構,頻寬維持在 20Gb/s,這點在目前日益增加的高速介面上,是非常不足的一個狀況。
另外在明年將會推出改進幅度更高的 Skylake,Haswell-E 能否坐滿 3 年旗艦,目前仍然是個問題,不過以 4 通道記憶體、8 核心處理器,仍然是非常有望在專業用途上取得絕對優勢。

請注意!留言要自負法律責任,相關案例層出不窮,請慎重發文!