ADVERTISEMENT
這次我們取得 HD 7970,除了一般性效能測試以外,還要測試所謂第一張「」顯卡有什麼能耐。而針對 GCN 架構,我們精心繪製了指令運作圖,讓大家了解 GPU 在多個 Wavefront 下,如何動態調度指令讓效率更高,也能看出 VLIW 4 跟 GCN 架構的差異。
快速瀏覽:
- AMD 挾 GCN 逆襲,圖解 Wavefront
效率不彰的VLIW
GCN(Graphic Core Next)是用於HD 7970的新架構,會讓AMD想要修改行之已久的架構,得要從先前(Very Long Instruction Word,超長指令集)體系說起。從R600也就是Radeon HD 2900系列之後,都使用(Single Instruction Multiple Data,單指令流多數據流)架構,也就是VLIW 5。到Cayman也就是Radeon HD 6970之後,才改為VLIW 4,但是架構設計上還是有缺憾。
4D架構還不夠好
5的特色在於使用4D+1D向量(vector)架構,對於經過最佳化的指令,能夠比使用的(Multiple Instruction Multiple Data,多指令流多數據流)更有效率。而VLIW 4則是拿掉4D+1D架構中的個1D成了4D架構,且透過升級後的4D,運算效能比傳統4D+1D更好,但是缺點就是電晶體數量增加,且功耗提升。
ADVERTISEMENT
關鍵字:純量與向量
3D物件的成像過程中,(Vertex Shader,頂點著色引擎)與(Pixel Shader,像素著色引擎)最主要的作用就是運算座標(XYZW)與顏色(RGBA)。此時數據的基本單位是scalar(純量),1個單位的變量操作,稱之為1D純量或簡稱1D。
而跟純量相對的就是(向量),向量是由多個純量構成。例如每個週期可執行4個向量平行運算,就稱為4D向量架構。若GPU指令發射口只有1個,卻可執行4個數據的平行運算,這就是SIMD架構。
GCN:圖形就是運算
理論上的最有效率不一定會印證在實際表現上,受到驅動程式與環境等限制,通常無法達到理論水準。更重要的是,以往VLIW 4或VLIW 5,在GPGPU(General-Purpose Computing on Graphics Processing Units,通用繪圖處理器)應用方面並不出色。
相對地,NVIDIA於GF 100使用的Fermi架構,對通用運算相當有力,讓這個領域的差距更為明顯,也興起改變架構的想法。早在去年AMD公佈GCN架構時,就已經喊出「圖形就是運算,運算就是圖形」的口號,透過架構升級,讓GCN能兼具圖形與通用運算。
VLIW 4/5架構對比圖
{kind=link}
{kind=link}
ADVERTISEMENT
(點小圖看大圖)
▲為了看出前後代差異,又得把這2張老圖拿出來。 5具備用於特殊運算的T unit(圖中體積較大者),而VLIW 4雖然看似精簡,但是每個ALU都能達到T unit的運算效能,因此表現會更好。而換架構也不是沒有缺點,即便ALU數量差不多,但是發射口與branch unit等元件增加,電晶體數量更多,不只拉高成本,功耗也跟著提升。HD 5870官方耗電量為188W,而HD 6970則是250W。
新增ECC校正
通用運算要強,除了架構支持,還得靠記憶體配合。首先是增加ECC(Error Checking and Correcting,錯誤檢查及校正)功能,可強化現有的EDC(Error Detection and Correction,錯誤檢測及校正)機制。
這2項設計都是為了保證高速GDDR5記憶體與系統記憶體資料交換的準確性, 早在GF 110時就已經具備ECC機制,而到Cayman之前只有EDC而沒有ECC。
ADVERTISEMENT
FP64納入架構標準
此外,針對精確度,也將FP64(double precision floating point,FP64,雙精度浮點數)納入新架構的標準,雖然FP64的峰值效能遠遜於FP32,但對於通用運算仍有其必要性。從GT 200之後支援FP64,而AMD則是從Cypress、也就是HD 5870開始支援。但是意外的是Barts(HD 6800系列)不支援FP64,直到Cayman(HD 6900系列)才又恢復支援。
關鍵字:FP32與FP64
▲經常聽到的單精度浮點數(single precision floating point,FP32)與(double precision floating point,FP64),都是IEEE 754二進位浮點算數標準的表示方式。其中單精度與雙精度的差異,主要在於前者的紀錄單位為32位元,後者則是64位元。依照紀錄位數的多寡,會影響到數值的精確度。因而在運算交換量龐大的通用計算中,具有更精準的雙精度運算會更好。
名詞對照 sign bit(符號) 用於表示正負號 exponent(指數) 用於表示次方數 mantissa(尾數) 用於表示精確度
效能也是改革關鍵
想要修正架構必定有其誘因,除了通用運算之外,先前的 5與VLIW 4效能不彰也是個問題。會採用VLIW體系,主要是受到3D影像的特性所影響。3D物件最重要的就是顏色與座標,其中顏色可由RGB三原色配上半透明通道alpha構成。而位置則是由三維座標XYZ,加上遠近參數W所構成的齊次座標來
3D物件變化時,顏色與座標的完全轉換都是4D純量,因此理論上用4D+1D的VLIW 5或4D的VLIW 4都能擁有最佳的效率。然而事實上並非如此,簡單來說,若要把黃色的皮卡丘變成淡黃色的皮卡丘,不用動到RGBA的4個參數,只要調整alpha參數即可得到淡黃色的皮卡丘。當需要運算1D純量時,架構內卻有3~4個ALU(Arithmetic Logic Unit,算數邏輯單元,等同Stream Processor)沒事幹,使用效率自然就不彰,偏偏這種情況又不算少。
ADVERTISEMENT
砍掉變成1D就好了
或許有人會說,那全都砍掉做成1D純量運算,問題不就解決了?的確如此,NVIDIA走的就是這個方式,將所有運算需求全部透過硬體將4D、3D、2D全都拆成1D,哪個CUDA Core(位階等同ALU或SP)閒著沒事就丟給它運算,實際使用率會比VLIW架構還好。
如果VLIW 5架構同時碰到1D、2D、3D與4D運算需求,最佳解就是將運算需求合併成1D+4D與2D+3D。如此一來只要1組運算單元跑2個週期或2組運算單元跑1個週期就能完成。AMD不透過硬體拆分指令串,便嚴格考驗驅動程式的最佳化能力,這也是為什麼有時AMD驅動程式一更新,效能立刻暴漲的原因,因為最初的版本最佳化肯定不好,得靠時間慢慢修正。
AMD:驅動成本高
(或是當初的ATI)會將架構設計為VLIW 5或VLIW 4,除了先前提到的效率之外,另一方面則是成本考量。不論VLIW 5或4都是透過驅動程式進行指令重組,並不像NVIDIA使用硬體架構進行重組。
這種架構好處是理論效率與效能很高,又沒了用於重組指令的硬體架構,更省電晶體。簡化硬體架構對於擴增ALU相對容易,尤其是更改製程的世代,能先透過擴增ALU的方式提高效能,把簡單的硬體架構先做出來,後期再靠驅動程式最佳化,還能把重組指令的硬體成本轉嫁到驅動程式上。
|
前後代卡王規格比較 |
||
| HD 6970 | HD 7970 | |
| 研發代號 | Cayman | Tahiti |
| 架構 | VLIW 4 | GCN |
| 製程 | 40nm | 28nm |
| 核心時脈 | 880 MHz | 925MHz |
| SP數量 | 1536 | 2048 |
| Texture Units | 96 | 128 |
| ROPs |
32 | 32 |
| 記憶體規格 | GDDR5 | GDDR5 |
| 記憶體容量 | 2GB | 3GB |
| 記憶體頻寬 | 176GB/s | 264GB/s |
| 最大電力需求 | 250W | 250W |
NVIDIA:硬體成本高
則是先設計完整的硬體架構,指令分配、運算都由硬體負責,驅動程式的重要性就不如,可節省驅動程式的開發費用。化整為零的方式,運算上較為單純,但是設計上較為複雜,算是一勞永逸的設計方式。
從過去同時期的核心來看,AMD的特色就是ALU數量多,但是跑的慢。代表的例子就是R600有320個ALU,時脈卻只有743MHz。NVIDIA的特色就是CUDA Core數量少,但是跑的快。代表核心G80只有128個CUDA Core,不過Shader時脈就有1.35GHz,可看出兩者設計上的差異。
Cayman與Fermi,數大不是美?
{kind=link}
{kind=link}
(點小圖看大圖)
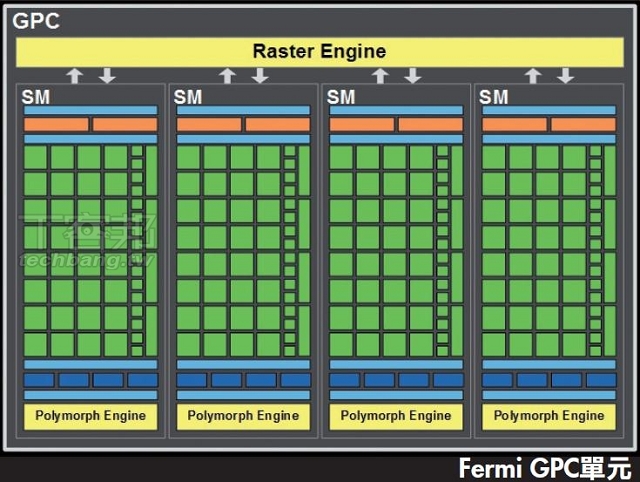
▲在GCN出現之前,Cayman與的基本運算核心不太相同,Cayman是以SIMD陣列為主,而Fermi則是以SM或是GPC為單位。同陣營顯卡中,若SIMD越多,或GPC、SM數量越多,通常就是效能的保證。但不同陣營的架構不同,比較兩者的ALU或CUDA Core是沒有意義的行為。
GPU成長趨緩
與的設計架構之間沒有絕對的優劣,各有擅長的領域跟成本考量。不過以架構的壽命來說,或許是擴增相對容易,AMD使用體系非常久,直到今日才大改成GCN,而NVIDIA在GT200後就改為架構,與最初G80的設計又大為不同。從架構的使用壽命來看,不難看出簡化硬體架構所帶來的設計優勢。雖然設計相對容易,但是要達到革命性的效能,還得要後期驅動程式配合,這也是AMD的弱項。近幾個世代,不論AMD或NVIDIA都沒有早期「半年架構一更新,核心效能倍增」的理想曲線,若要大幅提升效能,只強化既有架構是不夠的。
▲AMD這次不只架構改進,另外也將核心製程從40nm提升為28nm。顯而易見的好處就是耗電量、溫度更低,且超頻性表現也更好。
(下一頁:GCN:混血新架構)
延伸閱讀:
ADVERTISEMENT