
ADVERTISEMENT
2010年12月,Google與哈佛大學合作推出了科學實驗專案「Google Ngram Viewer」,大概可以翻譯為「Google圖書詞頻統計器」。
簡而言之,這個統計器是針對圖書出版物的一種「Google趨勢」。統計器提供關鍵字搜尋,搜尋的範圍是Google的數位圖書館「Google圖書」,分析關鍵字在圖書、報紙、期刊中出現的頻率,並按照年份依次排開,最終基於使用者給定的時間跨度,提供一條顯示關鍵字流行及發展趨勢的曲線。

在語言學範疇上,Google給定的文本範圍可以被稱作一種「語料庫」,而Google語料庫可能是迄今為止最大的人文及社會科學研究語料庫。
剛上線時,Google語料庫中擁有超過500萬本圖書,占世界上所有已出版書籍的4%,其中以英語書占多數。2020年7月,Google語料庫更新至2019版本,收錄從1500年到2020年2月的書籍文本,涵蓋英文、簡體中文、法文、德文等八種語言,圖書數量已超過千萬本。
Google表示,詞頻統計器得出的資料允許免費下載並用於任何用途,因此這項工具受到歐美學術界的熱烈歡迎與頻繁引用。
然而,更多的人把統計器用在了不那麼學術的用途上。在以造梗與玩梗著稱的網友中,流傳著這麼一種玩法:用詞頻統計器搜尋一些21世紀才出現的流行語及特有名詞,等待統計器提供一條令人細思恐極的曲線。
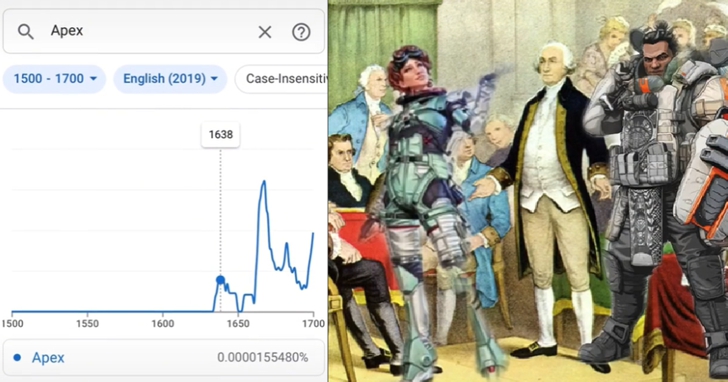
例如,在搜尋框輸入「Grand theft auto」——也就是GTA的全稱,你就會發現GTA在1770年左右擁有比21世紀還要高的詞頻。
也許,歷史老師在講授那段歷史時,有意向你隱瞞了些什麼。
1
詞頻統計器的這種玩法,是由法國人率先發現並大加傳播的。至少在第二次世界大戰之前,法國一直是公認的歐洲乃至世界強權,而詞頻統計器對那段歷史的學術研究貢獻之大,也許喚醒了他們對光榮時刻的追憶。
2020年7月27日,Google更新2019語料庫沒多久,法國網友PasEdward使用統計器的法語語料庫,搜尋了一個俚語單詞:「Wesh」。這個詞源自阿爾及利亞語,約在上世紀90年代傳入法國,意思相近於英文中的「What’s up」,中文裡的「嘿」或「發生了什麼」。
結果顯示,趨勢曲線在1800年的位置上出現了一次波折,意味著「Wesh」在1800年的著作中有使用記錄。雖然不明白原委,PasEdward還是把自己的發現放到推特上分享,同時配上一張簡陋的P圖,為法國大革命時期的著名政治家馬克西米連·羅伯斯比戴上了一頂現代帽子。
第二天,另兩位法國網友搜尋了一些歐洲歌手的名字,並在18-19世紀這一區間內找到了對應的索引結果。他們隨即把歌手的頭像P到法國國王路易十四與路易十六的畫像上,同樣上傳至推特。
不久,詞頻統計器的新玩法流傳至英語圈及短片APP TikTok。結合法國人的創作成果,短片作者們確立了一種兩段式的影片模式,為統計器成為新興網路梗奠定了基礎:
首先使用統計器搜尋當下的流行人物與事物,得到相關詞彙曾在21世紀以前被使用的記錄;然後動用P圖與剪輯技術,製造出可能用到這一詞彙的歷史場景。
時間快轉到2021年,統計器的熱度有所消退,可是又在法國人的努力下迎來了一次復興。
2021年10月10日,法國網友qouaa依照上面的格式製作了一部短片,他搜尋的詞彙是「Fdp」,意思與英文中的「Son of Bitch」(婊子養的)接近。趨勢曲線在1700年左右有所上漲,接下來的一幕中出現穿著潮牌說著髒話的路易十四,也顯得順理成章。
這則影片僅在一周內獲得了超過300萬次播放,也正式掀起了使用Google圖書詞頻統計器「考據」的風潮。從TikTok、Youtube,甚至到B站,相同格式的影片不斷湧現,影片作者致力於將那段「可能被埋沒的歷史」重現於世間,搜尋關鍵字也五花八門。
詞頻統計器告訴我們,16世紀有PC(個人電腦),17世紀有RGB(最常見的三原色),證明近代歐洲人已經在使用電腦,並且對電腦硬體上的彩光特效情有獨鍾。
硬體在發展,程式設計語言也在進步,1817年的程式師用Java寫個程式,好像也沒啥值得大驚小怪的。
詞頻統計器還顯示,17世紀以來的推特使用率居高不下;到了第一次世界大戰時期,才輪到短片應用紅極一時。
在音樂方面,麥可·傑克森的名號響徹了整整兩個世紀,而瑞克艾斯里大概從17世紀起就開始唱流行金曲了。
二次元文化也盛行了幾百年,據悉在第二次世界大戰爆發時,世界上最受歡迎的日本動漫是《火影忍者》。
把搜尋關鍵字換成今天的電子遊戲,同樣會得到令人們瞠目結舌的新發現:我們玩到的遊戲其實都是老祖宗們玩剩下的。
老祖宗們甚至有著在遊戲結束時打出「GG」(Good Game)的習慣,這大抵體現了他們對禮儀的規範與注重。
2
代表權威資料的Google圖書詞頻統計器,改出了太多令網友們啼笑皆非的「野史」。不過需要注意,統計器出現這種差之千里的謬誤,有時也不全是資料的錯。
假如你出於好奇打開統計器複現網友們的搜尋結果,就會發現一些結果與影片畫面對不上。影片作者可能透過修改網頁元素或者嫁接P圖、剪輯的方式,製作了假的趨勢曲線。
舉例而言,前文中提到過的Aimbot(自動瞄準機器人),在1893年以前的著作中毫無記載。
在B站有人查到「shabi」一詞最早在美國《獨立宣言》頒佈的1776年出現,這也不符合真實索引結果。至少在Google英語語料庫,這個詞的純小寫形式直到1824年才首次有人使用。
就算查到了與影片中一模一樣的趨勢曲線,也不代表真實索引結果具有足夠的說服力。網友們輸入的單詞或片語,可能對應多種含義,而Google的程式尚且無法做到劃分不同語義的程度。
例如,PC、RGB、GG等特定片語的縮寫形式,結合不同文本語境,可指代無數種具體事物;有時還會用作人名或機構名稱的縮寫。如果不進一步限定搜尋範圍,得到的結果不會有規律可循,自然缺乏應有的參考價值。
直接使用統計器搜尋某個人名,也不是值得過多提倡的行為。歷史記載中同名同姓者多如牛毛,更不用提外國人的人名大多出自聖經,擁有遠比中文誇張的重複率。
另外,TikTok與Twitter,本就是英語中的擬聲詞,在百餘年前的英文著作中出現也根本不稀奇。
當然,玩梗沒必要太過當真,本文也無意否定任何作者為了博觀眾一笑所耗費的大量心血,僅是指出在一部分影片中,作為工具本身的Google詞頻統計器沒什麼需要指摘的地方。
而在另一些關鍵字較為明晰的案例中,詞頻趨勢曲線在20世紀前的增長態勢有跡可循,使得統計器間接起到了反映歷史與社會變動的職責。
世界意義上的近現代史,正是各大洲各民族建立緊密聯繫的關鍵歷史時期,不同文化的交流與衝突,勢必為包括英語在內的各種語言帶來數不勝數的外來詞匯。
前文提到的Java在當下的語境中常指一種程式設計語言,放到殖民時期多半指的是16世紀初由葡萄牙殖民者發現的東南亞爪哇島。今天的Anime是由日語的「動漫」一詞音譯而來,然而百餘年前的英國水手聽到這個詞,頂多聯想到美洲大陸出產的某種樹脂。
![]() Shabi一詞在19世紀出現幾率很高,是因為英國的殖民統治達到鼎盛,進而與東方文明產生了空前的交流。Shabi常出現在與中國、印度、阿拉伯文化相關的英文著作中,指代的意思各不相同,放到中國是「沙弼」,即沙彌、小和尚一詞的音譯;放到阿拉伯語裡就變成了慣用的人名。
Shabi一詞在19世紀出現幾率很高,是因為英國的殖民統治達到鼎盛,進而與東方文明產生了空前的交流。Shabi常出現在與中國、印度、阿拉伯文化相關的英文著作中,指代的意思各不相同,放到中國是「沙弼」,即沙彌、小和尚一詞的音譯;放到阿拉伯語裡就變成了慣用的人名。
3
雖然我們使用統計器的方法有時不太科學,但Google的工具也絕非完美無瑕。事實上,早在Google圖書詞頻統計器誕生始於的2010年,就已經有學者吐槽過某些21世紀特有名詞在語料庫中的「穿越」現象。
網友們頗有微詞時會把微詞變成梗,而學者們的微詞會變成學術研究與學術論文。近幾年來的研究調查證明,Google的資料也沒那麼權威,其統計器與語料庫存在的問題可不少。
最致命的問題是文本掃描錯誤。將圖書掃描成電子文本所使用的光學字元辨識技術,簡稱OCR,其可靠程度會根據圖書的印刷品質產生浮動,在讀取百餘年前的文本時總是會出錯。
以前的英文著作經常把字母s寫作作形近於字母f的「長s」,直至18-19世紀印刷技術取得長足進步,「長s」才漸漸消亡。Google的OCR一度識別不出「長s」,導致許多帶有s與f字母的單詞之間產生可怕的混淆,直至2019年Google語料庫更新,這一錯誤才得以大幅修正。
但有些相比之下並不明顯的錯誤至今依然存在。就以網友們玩梗提出的那些關鍵字為例,把Google圖書的搜尋結果搬來和統計器作下對比,便會明白OCR偶爾會錯到十分離譜的地步。
19世紀及以前的英文印刷品經常出現每行或每頁末尾寫不下完整單詞的情況,印刷商會在沒寫完的單詞後接上一根橫杠「-」,讓讀者去下一行或下一頁找到單詞的後半部分。正是這個「-」,會被OCR識別成字母,像是「pub-」,就會出現在《絕地求生》縮寫「pubg」的搜尋結果中。
一些形近意思卻完全不同的單詞或片語,對於OCR而言亦是災難。如「Infernet」,這個法國人的姓氏經常被錯認為「Internet」(網際網路);「fortune」(幸運)或是「for these」(為了這些),更是會被陰差陽錯地識別成《要塞英雄》的英文名「fortnite」。
Google掃描圖書時,需要填充圖書的標題、出版日期、作者、頁數等中繼資料。這一過程與OCR類似,都由程式自動進行,因此也有漏洞。
文章開頭影片中的GTA,即「grand theft auto」,在美國對應一種盜竊機動車的罪名。在Google圖書搜尋「grand theft auto」,並把搜尋時間限定至18世紀的話,我們會查到一部實際在1981年出版、文中多次提到GTA的美國加利福尼亞州議會法案,它的出版日期被Google錯標成了「1771年」。
單是這一本書的標注錯誤,就貢獻了一條篡改歷史的趨勢曲線和一部讓數百萬人忍俊不禁的玩梗影片。如今各個影片網站類似的影片數以千計,而語料庫中OCR與中繼資料出錯的文獻,恐怕還不止這個數量。
當然,任何科學測量工具都不可能做到百分百完美,資料與演算法也不例外。能夠在短短數秒之內完成定量分析,得出某種事物在數百年中的大致發展動向,正是Google圖書詞頻統計器的價值所在。
不過,在這個語料庫不知何時才有的下一次更新之前,這些謬誤將一直作為網友們造梗的源泉而存在,這大概是開發者所沒有想到的了。
- 本文授權轉載自遊研社

請注意!留言要自負法律責任,相關案例層出不窮,請慎重發文!