
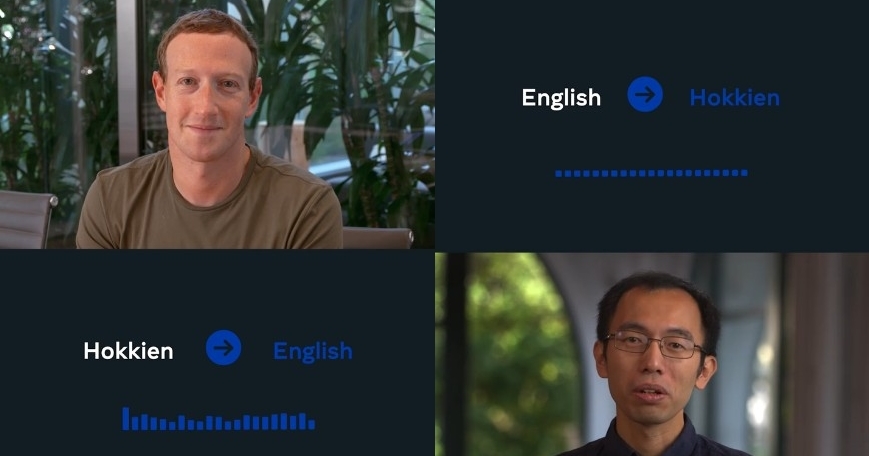
Meta 執行長祖克柏昨天在 Facebook 上貼出一段英語與閩南語 AI 口譯翻譯對話的影片,並表示目前正在開發 AI 口語翻譯系統,讓主要用於口說而非書寫的語言(例如閩南語)可以被翻譯。
與祖克柏對話的這名員工,是來自台灣的 Meta AI 研究員陳鵬仁,從小在台灣長大講的是一般的中文,但是他爸爸講的是台語,他表示能明顯感受到語言障礙影響溝通的能力,因此希望能改善這個問題。
為開發這個只有語音的全新翻譯系統,Meta AI 研究人員必須克服許多來自傳統機器翻譯系統的挑戰,包括資料蒐集、模型設計,以及準確度評估。在將 UST 擴展至更多語言之前,Meta 還有很多工作要做。
但能夠輕鬆地與使用任何語言的人們溝通的能力,是 Meta 長久以來追尋的夢想,因此 Meta 很高興能向這個目標更邁進了一步。Meta 不只會開放閩南語翻譯模型的原始碼,也會公開評估資料集和研究報告,讓他人能夠重製並以 Meta 的工作成果為基礎建立模型。
「我希望我爸跟所有人溝通時,都用台語,這是他最熟悉的語言。」Meta AI研究員陳鵬仁分享,「他聽得懂中文,但若是討論比較複雜的主題時,他說話的速度會比較慢。」
Meta 今日發出新聞稿表示,截至目前為止 AI 翻譯主要著重於各種書寫語言,但在全球超過 7,000 種的現存語言中,將近半數主要是以口語表達,沒有標準或廣泛使用的書寫文字系統,導致 AI 無法使用標準技術為這類以口語為主的語言打造機器翻譯工具。
為了克服這個挑戰,Meta 以「閩南語」這項以口語為主的語言打造了人工智慧技術翻譯系統,讓使用閩南語口說的人可以直接和使用英語口說的人對話。

該開放原始碼的翻譯系統是 Meta Universal Speech Translator(UST,或譯:通用語音翻譯工具)專案的一部分,該專案致力於開發新的 AI 方法,希望最終能為所有現存語言進行即時語音翻譯,包括主要以口語表達的語言。
克服訓練資料的挑戰
在著手打造閩南語翻譯系統時,面臨的一個重大障礙就是是否能夠蒐集到足夠的資料。
閩南語是所謂的資源匱乏語言,這意味著與西班牙文或英文等語言相比,該語言尚未有足夠的訓練資料,此外,將英語翻譯成閩南語的翻譯人員相對來說很少,因此更難以蒐集資料並加上註解來訓練模型。
Meta 利用中文作為中間語言,以建立偽標籤和人工翻譯,意思是 Meta 先將英語(或閩南語)語音翻譯成中文文字,接著再翻譯成閩南語(或英語),然後新增至訓練資料中。此方法利用了資源充足的相似語言的資料,藉此大幅改善了模型成效。
另一個產生訓練資料的作法是語音探勘,Meta 使用預先訓練好的語音編碼器,便能透過編碼方式將閩南語語音嵌入內容加入到其他語言的相同語意空間中,而無須取得閩南語的書寫文字。閩南語語音可以和擁有相似語意嵌入內容的英語語音和文字配對,接著從文字來合成英文語音,產生平行的閩南語和英語語音。
全新的模型作法
許多語音翻譯系統依賴轉譯內容,或依賴語音轉文字系統,但由於主要以口語表達的語言並沒有標準書寫文字形式,因此 Meta 就無法將翻譯的文字製作成翻譯內容輸出,因此在這個模型中,Meta 聚焦於語音轉語音翻譯。
Meta 使用語音轉單元翻譯(speech-to-unit translation,S2UT)系統,直接在先前由 Meta 開創的路徑中,將輸入的語音翻譯成一系列聲學單元,然後從這些單元中生成波形。此外,針對二次解碼機制採用 UnitY,讓第一階段的解碼器產生相關語言(中文)的文字,然後讓第二階段的解碼器製作單元。
評估準確度
語音翻譯系統通常會使用稱為 ASR-BLEU 的衡量指標來評估,首先需使用自動語音識別系統(ASR)將翻譯後的語音轉譯成文字,然後將轉譯後的文字與人工翻譯的文字比較,以計算 BLEU 分數(標準機器翻譯衡量指標)。
但評估主要以口語表達的語言(例如閩南語)時,評估語音翻譯的挑戰之一就是沒有標準的書寫文字系統,為啟動自動評估程序,我們開發了稱為 Tâi-lô 的系統(Tâi-lô,台羅),將閩南語語音轉譯成標準化的拼音符號。這項技術讓 Meta 能以音節為單位計算 BLEU 分數,並能夠很容易地比較不同方法下的翻譯品質。
除了開發方法以評估閩南語與英語語音翻譯的準確度,Meta 也根據名為 Taiwanese Across Taiwan 的閩南語語音語料庫,建立第一個閩南語與英語雙向的語音翻譯基準資料集。Meta 將開放此基準資料集的原始碼,以鼓勵其他研究人員合作進行閩南語語音翻譯,並一同在該領域中取得進一步進展。
展望翻譯的未來
在目前的階段中,Meta 的作法能夠讓使用閩南語的人士與使用英語的人士對話。雖然該模型仍在開發中,而且每次只能翻譯一個完整句子,但已朝著未來實現為各種語言提供同步翻譯的目標邁開一步。
Meta 首創用於閩南語的各項技術,可以擴展至許多其他有書寫系統和無書寫系統的語言。為此,Meta 將發佈 SpeechMatrix(暫譯語音矩陣),這是由 Meta 的創新資料探勘技術支援的大型語音翻譯語料庫,稱為 LASER,能讓研究人員建立自己的語音翻譯(S2ST)系統,並以 Meta 的工作成果為基礎,展開研究及開發工作。
此外,Meta 在非監督方式語音識別技術(wav2vec-U)與非監督方式機器翻譯(mBART)上的最新進展,將有助於未來能翻譯更多口說語言的工作。隨著在非監督學習上的進展,Meta 證明了在沒有人工註解下建立高品質的語音轉語音翻譯模型的可行性。這將大幅降低往後擴展至低資源語言的條件,因為其中大部分的語言都沒有獲得標記的資料。

請注意!留言要自負法律責任,相關案例層出不窮,請慎重發文!