
無需文字標籤,完全自監督的 Meta 視覺大型語言模型來了!
這還是由祖克柏親自發佈,收穫大量關注度 ——在語義分割、實例分割、深度估計和圖像檢索等任務中,這個名叫 DINOv2 的視覺大型語言模型均取得了非常不錯的效果。

甚至有超過當前最好的開源視覺模型 OpenCLIP 之勢。
雖然先前 Meta 就發佈過自監督學習視覺大型語言模型 DINO,不過這次 AI 識別圖像特徵的能力顯然更進一步,精準分割出了影片中的主體:
可別以為 DINOv2 通過自監督學會的只有圖片分割。事實上,它已經能根據不同類別、不同場景下的照片,精準識別出同種物體(狗)的頭部、身體和四肢長在哪:
換而言之,DINOv2 自己學會了找圖像特徵。
目前 Meta 官方不僅已經放出了開放原始碼,而且還給了網頁版 Demo 試玩。有網友說:什麼叫開源,LLaMA,SAM,DINOv2 這才叫開源!
一起來看看,DINOv2 的效果究竟如何。
精準識別不同畫風的同種物體
事實上,DINOv2 是基於上一代 DINOv1 打造的視覺大型語言模型。
這個模型參數量是 10 億級,也仍然是視覺 Transformer 架構(ViT),但與 DINO 不太一樣的是,這次 DINOv2 在資料集上經過了精心挑選。
具體來說,DINOv2 建構了一個資料篩選 pipeline,將內容相似的圖片精心篩選出來,同時排除掉相同的圖片:
最終呈現給 DINOv2 的訓練資料圖片雖然沒有文字標籤,但這些圖片的特徵確實是相似的。
採用這類資料訓練出來的視覺模型,效果如何?
這是 DINOv2 在 8 個視覺任務上的表現,包括語義分割、分類、深度估計等,其中橙色是自監督方法的效果,深粉色是弱監督方法的效果。
可以看見,經過自監督學習的視覺模型,表現上已經與經過弱監督學習的模型性能相當。
實際效果也不錯,即便在一系列照片中,相同物體的畫風並不相似,DINOv2 也能精準識別它們的特徵,並分到相似的列表中。
如(a)組中都具有翅膀的鳥和飛機、(b)組中的大象和大象雕塑、(c)組中的汽車和汽車玩具模型、(d)組中的馬和塗鴉版馬:
而且從 PCA(主成分分析)圖像效果來看,DINOv2 不僅能精準分類,還能用不同顏色標出它們“相同”的部分,例如象鼻都是綠色、車輪都是紅色、馬的尾巴是黃色等。
換而言之,DINOv2 能理解這些圖像中的相似之處,就像人會形容飛機“看起來像一隻鳥”一樣。
目前 DINOv2 已經放出 Demo,我們也試了試它的實際效果。
Demo版本開放直接可玩
官網已經開放語義分割、圖像檢索和深度估計三大功能的試玩。
DEMO網頁為:https://dinov2.metademolab.com/?fbclid=IwAR3xxhl1PFg7WKG8EcWQHgqi8WO8lDtQxaNVtPl8uSrWU2qOwgAB_i7OPb8
據 Meta 介紹,這幾個任務中,DINOv2 在大多數基準上超過了目前開源視覺模型中表現最好的 OpenCLIP。
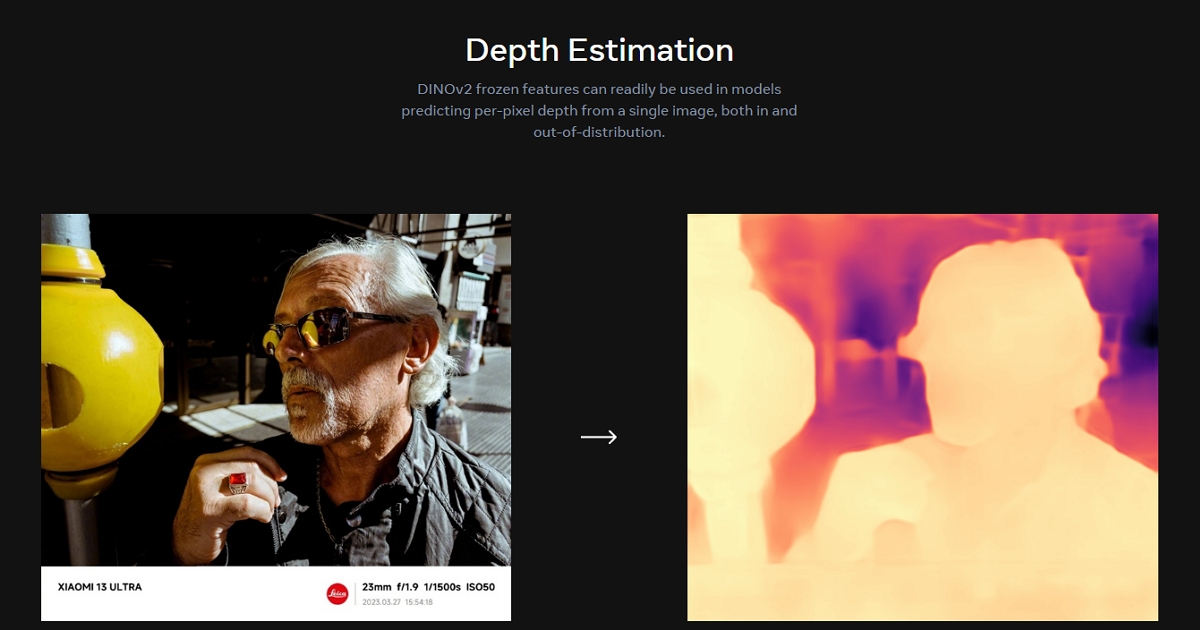
我們先來看看深度估計的效果。
值得一提的是,在效果更好的情況下,DINOv2 運行的速度也比 iBOT 更快,相同硬體下只需三分之一的記憶體,運行速度就能比 DINOv2 快上 2 倍多。
這是 Meta 論文中與 OpenCLIP 在實際例子上的比較效果:
接下來是語義分割的效果,這裡也先給出 Meta 論文中的資料對比情況:
這裡也給出 OpenCLIP 和 DINOv2 的對比,中間的圖片是 OpenCLIP 的效果,右邊是 DINOv2 分割的效果:
我們也用一張辦公室的圖片試了一下,看起來 DINOv2 還是能比較準確地分割人體、物體的,但在細節上會有一些噪點:
最後是圖片檢索:
輸入一張華強買瓜,給出來的藝術圖片大多數與西瓜有關:
那麼,這樣的自監督視覺大型語言模型可以用在哪里?
從 Meta 給出的內容來看,目前有一些比較環保的用途,例如用於估計全球各地的樹木高度:
除此之外,如同祖克柏所說,DINOv2 還能被用於改善醫學成像、糧食作物生長等。當然這裡小扎還進一步強調:
可以被用於製作更具沉浸感的元宇宙。
嗯,看來 Meta 的元宇宙路線還將繼續……
試玩 Demo 地址:
https://dinov2.metademolab.com/demos
項目地址:
https://github.com/facebookresearch/dinov2
參考連結:

請注意!留言要自負法律責任,相關案例層出不窮,請慎重發文!